

벌써 약 2년 전 일이 되었긴 하나, 한 코테에서 해결하지 못하면서 정말정말 아쉬움이 남는 문제가 바로 이 문제였다.
끝나고 메모장에 휘갈겨 쓰면서 문제를 다시 복기했던 기억이 난다.
깃헙에 적어뒀던 링크: 바로가기
특정 유저와 친구인 사람이 한 명씩 등록되어 있다고 해보자. 일반적인 친구 목록과는 달리 한 유저에 한 유저씩 등록되어 있었다. A와 B가 친구고 B가 C와 친구면 B는 A와 C의 mutual friend라고 할 수 있다. 두 계정 사이에 mutual friends가 많을 수록 현실에서 친구일 가능성이 높다. 즉 A와 C는 B같은 친구가 많을수록 실제 친구일 가능성이 높은 것. 특정 계정과 친구일 가능성이 가장 높은 친구를 검색한다.
겹치는 친구가 있는 친구사이를 mutual friend라고 부르는데, 특정 계정과 친구일 가능성이 가장 높은 친구를 검색하는 문제였다.
요즘 데이터리안 SQL 실전반을 듣고있는데, correlated subquery 강의를 듣고 문득 해결할 수 있겠다라는 생각이 들었던 것이었다.
(혹시나 비슷한 케이스가 있지 않을까 당시에도 찾아보았었는데 stackoverflow에서 찾을 수 있었다.)
하지만 그 자신감은! 근거가 없었고 ㅋㅋㅋ 비슷한 케이스를 찾아 데이터부터 받아왔다. (아래 유튜브 영상 유튜버의 블로그!)
오답일지
나는 옆으로 친구들을 붙일 생각들을 했던 것 같다.
옆으로 붙여서 이어져있는 친구들을 찾는다, 그래서 문제에서 주어진 사람을 기준으로 친구별 겹치는 친구 명수를 찾아서 내놓을 생각을 했었는데 이게 머리에서 확실하게 정리가 안되다 보니 더 어려웠던 것 같다.
SELECT f1.friend1
, f1.friend2
, f2.friend2
FROM Mutual_Friends f1
LEFT JOIN Mutual_Friends f2 ON f1.friend2 = f2.friend1
;
-- 위와 같은 결과를 내는 코드
SELECT friend1
, friend2
, (SELECT friend2 FROM Mutual_Friends f2 WHERE f1.friend2 = f2.friend1) AS friend3
FROM Mutual_Friends f1
;
풀이 영상 참고
이러한 문제를 해결하는 유튜브 영상도 있다. (eng)
https://www.youtube.com/watch?v=ka9kDqkITX4
데이터는 이 분의 영상의 info에 있는 이 분 블로그에서 가져왔으며 이름은 임의로 바꾸었다. (플리 열어서 이름만 가져왔다 😍)
풀이는 다음과 같다.
1. 먼저 데이터를 보자. friend1에 없는 사람도 있기 때문에 UNION ALL이 필요하다. (서로의 쌍이 중복이 된 경우는 없다. 말하자면 Ruel-Isac가 있고 Isac-Ruel이 또 있지는 않다.)

이들을 UNION ALL 한 결과이다.
SELECT friend1, friend2
FROM Mutual_Friends2
UNION ALL
SELECT friend2, friend1
FROM Mutual_Friends2
ORDER BY 1;
2. 그리고 UNION한 결과를 WITH로 임시 테이블을 만들어두고 원래의 MUTUAL_FRIENDS2 테이블과 연결을 하도록 해보자.
(그렇지 않고 원래의 테이블에서만 조회하면 Jeremy의 친구는 Isac 하나밖에 조회되지 않는다.)
WITH all_friends AS
(
SELECT friend1, friend2
FROM MUTUAL_FRIENDS2
UNION ALL
SELECT friend2, friend1
FROM MUTUAL_FRIENDS2
)
SELECT *
FROM MUTUAL_FRIENDS2 f
JOIN all_friends af ON f.friend1 = af.friend1
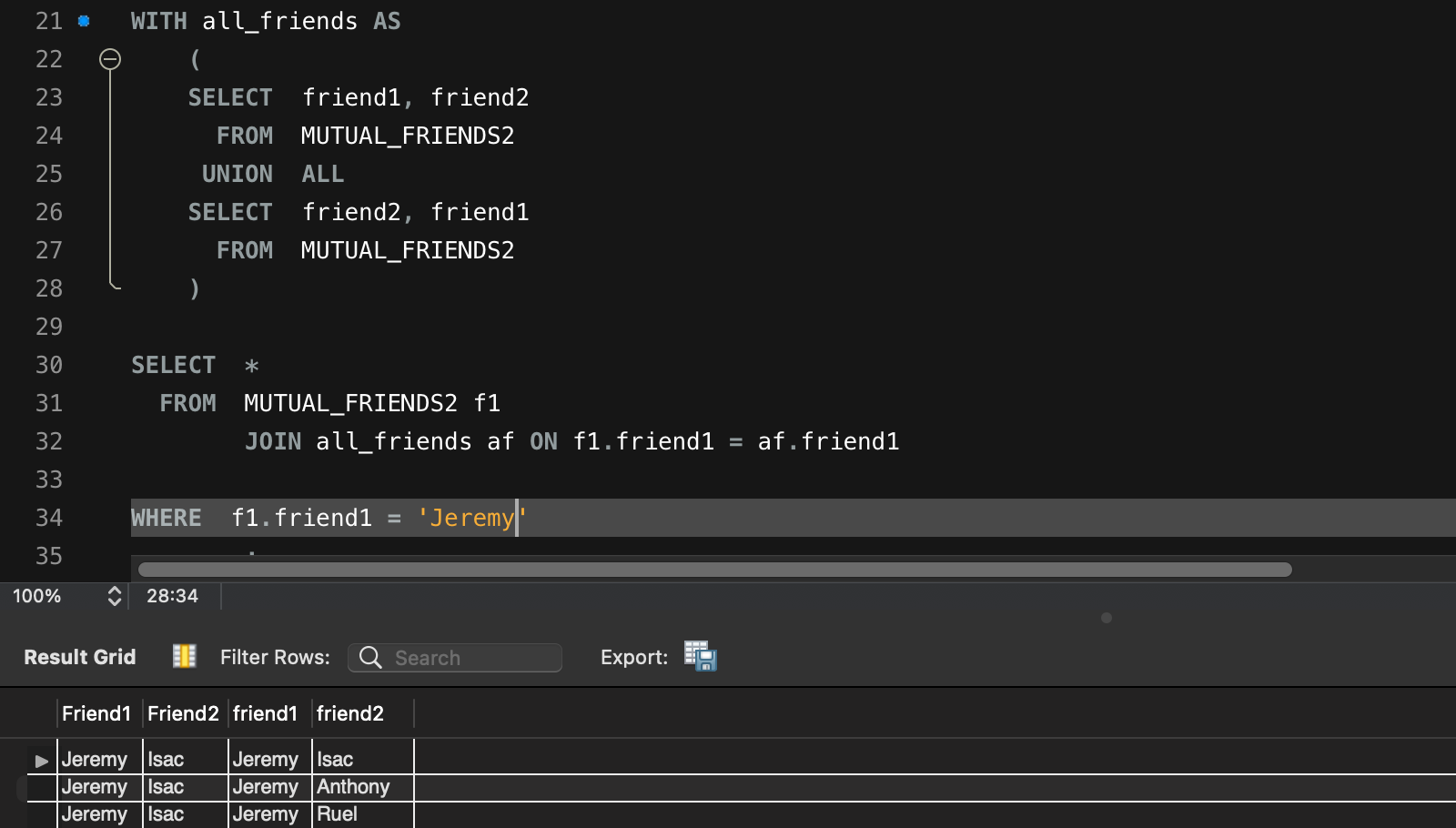
WHERE f.friend1 = 'Jeremy'
;이렇게 하면 다음과 같은 결과를 만날 수 있다.
3. 공통이면 출력이 되게 하고, 공통이 아니면 출력되지 않도록 하는 것을 목표로 한다고 해보자.
예를 들어 Jeremy의 친구는 Jeremy는 Isac, Anthony, Ruel 이다. 3 행이다.
이중 Isac은 Jeremy, Anthony, Shawn, Ruel과 친구로, 4 행이다.
(이 둘은 Anthony와 Ruel이 겹치게 된다.)
따라서, 이제 다른 조건을 붙이려고 한다. Jeremy에 대해서 가져왔었다면 이번엔 Isac에 대해서 가져오는 것이다.
조인을 시키면서 f1.friend2에 특정 한 사람의 친구들을 모두 데려왔다면, 이번엔 그 사람의 친구에 대해 친구들을 데려오는 것이다.
바로 저 조인조건에 끌고온다.
WITH all_friends AS
(
SELECT friend1, friend2
FROM MUTUAL_FRIENDS2
UNION ALL
SELECT friend2, friend1
FROM MUTUAL_FRIENDS2
)
SELECT *
FROM MUTUAL_FRIENDS2 f
JOIN all_friends af
ON f.friend1 = af.friend1 -- (1) Jeremy라는 정보를 일치시킴
AND af.friend2 [ ? ] ( -- af.friend2는 Jeremy의 친구를 담고있으며, 친구의 친구를 거를 곳 즉 Isac의 친구들을 데려와 비교할 곳
SELECT af2.friend2 -- (3) Jeremy의 친구의 친구
FROM all_friends af2
WHERE af2.friend1 = f.friend2) -- (2) Jeremy의 친구라는 조건
WHERE f.friend1 = 'Jeremy'
;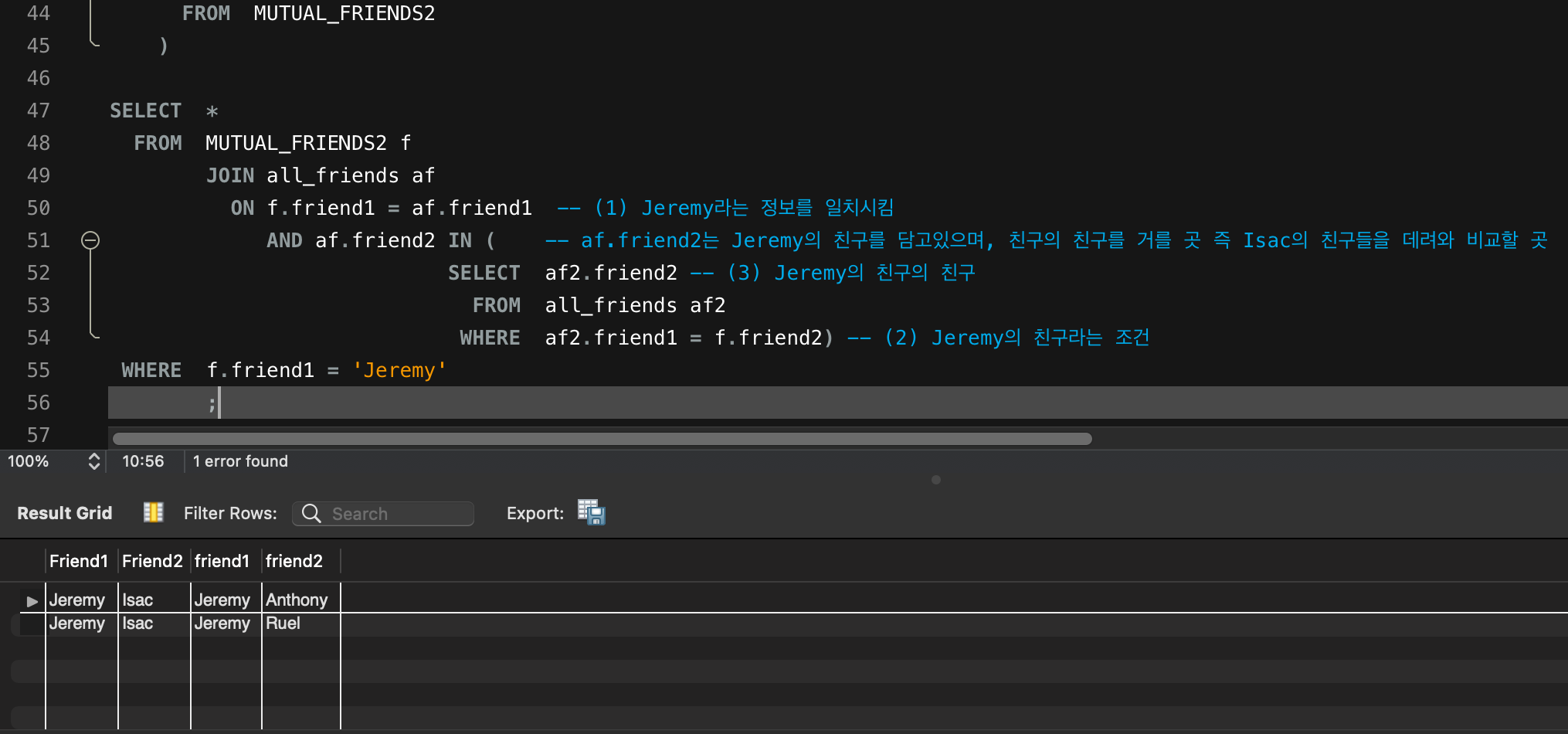
만약 저 IN 뒤의 쿼리는 Jeremy의 친구라는 조건 하에, 그 친구의 친구들을 불러오게 된다. (단독 실행하며 이해를 위해 임시쿼리를 FROM절에 넣음)
-- 만약 af2부분을 실행시킨다면 이렇게 될 수 있다.
SELECT af2.friend2 -- (3) Jeremy의 친구(f.friend2)의 친구 : 즉 Isac의 친구들(Jeremy포함)
FROM (
SELECT friend1, friend2
FROM MUTUAL_FRIENDS2
UNION ALL
SELECT friend2, friend1
FROM MUTUAL_FRIENDS2
) af2
WHERE af2.friend1 = 'Isac';
4. 자 그럼 3번에서 [ ? ]로 구멍이 뚤린 곳에 넣을 것이 생각이 날 것이다. IN!
WITH all_friends AS
(
SELECT friend1, friend2
FROM MUTUAL_FRIENDS2
UNION ALL
SELECT friend2, friend1
FROM MUTUAL_FRIENDS2
)
SELECT *
FROM MUTUAL_FRIENDS2 f
JOIN all_friends af
ON f.friend1 = af.friend1 -- 메인쿼리에서는 첫 번째 친구 즉 Jeremy의 친구들을 담고 있음: 3개
AND af.friend2 IN ( -- af.friend2는 Jeremy의 친구를 담고있으며, 친구의 친구를 거를 곳 즉 Isac의 친구들을 데려와 비교할 곳 :4개
SELECT af2.friend2
FROM all_friends af2
WHERE af2.friend1 = f.friend2)
WHERE f.friend1 = 'Jeremy'
; -- 실행하면 마지막 컬럼에 Anthoyny 와 Ruel이 정상적으로 출력됨
5. 이젠 Jeremy만이 아닌 각 친구 쌍에 따라서 모두 출력되도록 해보자.
WHERE 절을 지우기만 하면 된다.
WITH all_friends AS
(
SELECT friend1, friend2
FROM MUTUAL_FRIENDS2
UNION ALL
SELECT friend2, friend1
FROM MUTUAL_FRIENDS2
)
SELECT f.*
, af.friend2 AS mutual_friends
FROM MUTUAL_FRIENDS2 f
JOIN all_friends af
ON f.friend1 = af.friend1 -- 메인쿼리에서는 첫 번째 친구 즉 Jeremy의 친구들을 담고 있음: 3개
AND af.friend2 IN ( -- af.friend2는 Jeremy의 친구를 담고있으며, 친구의 친구를 거를 곳 즉 Isac의 친구들을 데려와 비교할 곳 :4개
SELECT af2.friend2
FROM all_friends af2
WHERE af2.friend1 = f.friend2)
-- WHERE f.friend1 = 'Jeremy'
ORDER BY 1
이렇게 실행하면 공통 친구를 가진 사이끼리 6행이 출력이 된다.
이때 Shawn은 아예 나타나지 않게 되는데 Shawn은 유일하게 Isac과 친구이며 그 둘 사이엔 mutual_friend가 없기 때문이다.
만약 mutual_friend가 없더라도 출력하게 하고싶다면 메인 쿼리의 JOIN을 LEFT JOIN으로 하면 된다.
6. 그럼 LEFT JOIN을 해보자. 또한 WINDOW 함수로 COUNT까지 해주기로 한 상태이다.
WITH all_friends AS
(
SELECT friend1, friend2
FROM MUTUAL_FRIENDS2
UNION ALL
SELECT friend2, friend1
FROM MUTUAL_FRIENDS2
)
SELECT f.*
, af.friend2 AS mutual_friends
-- (2) WINDOW 함수로 세기 : 다중컬럼 비교시 "f.friend1, f.friend2" 처럼 나열하기!
, COUNT(af.friend2) OVER (PARTITION BY f.friend1, f.friend2 ORDER BY f.friend1, f.friend2
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS cnt
FROM MUTUAL_FRIENDS2 f
LEFT JOIN all_friends af -- (1) LEFT JOIN으로 바꿈
ON f.friend1 = af.friend1
AND af.friend2 IN (
SELECT af2.friend2
FROM all_friends af2
WHERE af2.friend1 = f.friend2)
ORDER BY 1
;
이젠 Shawn도 잘 나오는 것을 확인할 수 있다!
이 다음은 필요없는 컬럼인 mutual_friend를 지우는 것이었는데 벤더가 달라서인지 안되서 관둠
-- 7 표시:
-- af.friend2를 지우는 것 : 이사람은 되었으나 난 안됨(postgre sql 쓴다고 했음)
(
SELECT friend1, friend2
FROM MUTUAL_FRIENDS2
UNION ALL
SELECT friend2, friend1
FROM MUTUAL_FRIENDS2
)
-- 바로 이 SELECT 절을 저렇게 썼는데 결과가 나오더라
SELECT f.*--, af.friend2 AS mutual_friends
, COUNT(af.friend2) OVER (PARTITION BY f.friend1, f.friend2 ORDER BY f.friend1, f.friend2
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS cnt
FROM MUTUAL_FRIENDS2 f
LEFT JOIN all_friends af
ON f.friend1 = af.friend1
AND af.friend2 IN (
SELECT af2.friend2
FROM all_friends af2
WHERE af2.friend1 = f.friend2)
ORDER BY 1
;
나중에 비슷한 문제를 마주하게 된다면
만약 데이터 생김새가 이런 데이터면 모르겠는데, 실제로 현업에서 데이터를 가져와 쓴다고 하면 유저들의 범위를 지어서 그 범위의 유저들만 가지고(mutual friend의 주체, 짝, Isac과 Jeremy) 해야하는걸까도 싶고, 그렇게 되면 mutual friend의 근거(Anthony, Ruel)는 되지만 대상은 되지 못하는 유저들이 생기지 않을까 싶다. 그렇다면 어딘가 데이터 빠진 데이터 분석이 되겠지..?
모든 유저를 대상으로 한다면 그 많은 유저들의 짝을 묶는데 있어서 엄청 많은 짝이 생길 것 같다. 그렇다면 기본적으로 친구가 많은(5명인지 20명인지 많다의 기준도 정해야겠지만) 유저들을 대상으로 분석을 해야할 것 같다.
'SQL' 카테고리의 다른 글
| 1주차 EDA (0) | 2024.05.12 |
|---|---|
| 데이터 분석기법 - 리텐션 (0) | 2024.05.11 |